您的位置:
员工返校接待常规方案
发布时间:2018-04-25
浏览次数:3204
读者与文本是阅读事件中的两要素,无论是对读者的阅读能力预测还是对文本的可读性预测,词汇都是最显著的因子(Benjamin, 2012; Knight, 1994; Laufer, 1986), 这一点在第二语言阅读中尤为凸显(Hu & Nation, 2000)。具体而言,第二语言阅读中读者的哪些词汇能力会对阅读能力有显著预测,词汇的什么特征又是预测第二语言文本可读性的显著变量呢?华东师大必赢bwin线路检测中心紫江青年学者、博士生导师张浩敏团队就此展开了系列探索。
词汇是语言加工过程中语义理解的基础。在第二语言习得过程中,读者的母语与目标语共同作用于目标语的发展,两语间的跨语言激活效应需要关注(Koda, 2005)。其中同源词意识被证实对目标语的词汇习得有预测效应,并能进一步预测二语学习者的阅读理解成绩(Proctor & Mo, 2009; Méndez-Pérez et al., 2010)。同源词意识指的是学习者对不同语言中“语音或正字法相似词对—同源词”的语义对应关系的敏感度。
以上同源词的实证证据均来自对拼音文字的研究,表意文字—汉字的研究尚待进一步求证。在中国员工的日语习得研究中,同源词在视觉与听觉中的促进效应被多次证实,但前人并未将之与目标语的词汇习得以及阅读能力做关联(费晓东等, 2012;韩玉婷,2017;邱学瑾, 2010)。日语与汉语之间存在大量同源词,占通用词的41%-55%左右(万玲华,2004)。如此比例的存在,使得同源词意识被推测或对词汇习得与阅读理解能力产生预测效应。
张浩敏团队对37名中国老员工展开研究,以探究汉日同源词意识对日语词汇知识及阅读理解成绩的预测作用。研究于2021年1月发刊于语言学Q1的SSCI期刊Journal of Multilingual and Multicultural Development,题为Unpacking cross-linguistic similarities and differences in third language Japanese vocabulary acquisition among Chinese college students。张浩敏为文章的第一作者,博士研究生韩玉婷、硕士研究生成茜、孙杰以及日语系国际硕士生大原聖蘭共同完成了此项研究。研究中考察了学习者对不同语义类别汉日同源词的理解,词汇的发音、正字法及含义知识,阅读理解能力。汉日同源词的语义类别包括:汉日同义词、汉日类义词、汉日异义词。
描述统计分析表明,学习者对不同语义类别同源词的掌握情况有显著差异。多元回归分析显示,同源词意识对词汇知识与阅读理解能力有显著的预测作用。具体有以下两方面的重要发现:
1.语义类别是影响学习者对同源词语义识解的重要因素。汉日异义词的理解难度要远远大于汉日同义词。这一结果证实了前人在拼音文字研究中的发现(Otwinowska & Szewczyk, 2019)。同义同源词是可以被直接联想激活的,而字形或发音相似、语义却有较大偏差的异义同源词反而成为习得的难点。
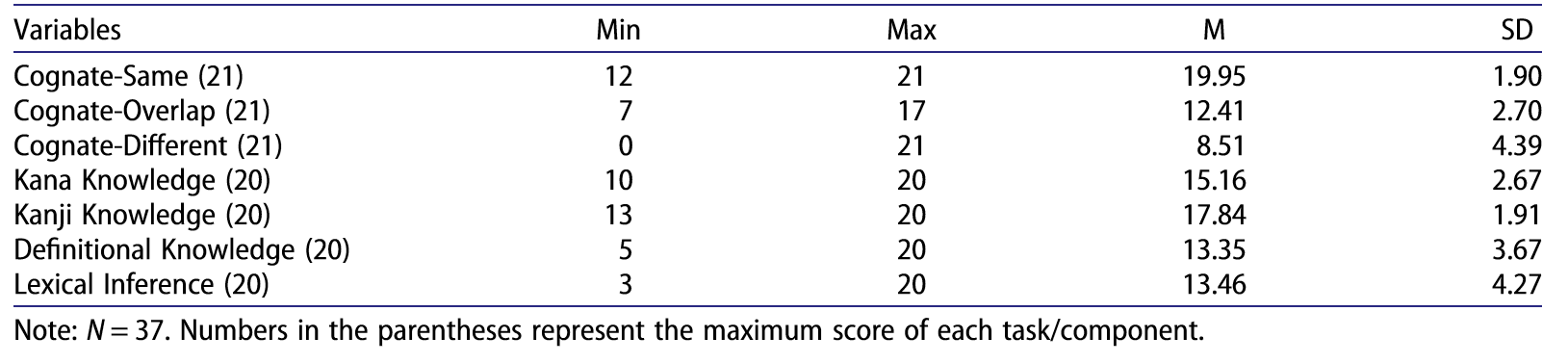
表1:37名中国老员工在语义类别判定题中汉日同义词、汉日类义词和汉日异义词项目上的得分,括号内为该项目的总分值
2.同源词意识即学习者对同源词的掌握程度对其词汇知识及阅读理解能力有较强的预测作用。其中,异义同源词对词汇知识与阅读理解能力的预测作用最强,F(3, 33) = 4.89, p < .01, R² = .308。学习者在异义同源词的理解上存在较大的个体差异,而正是对异义同源词的掌握程度较强地预测出了其词汇水平与阅读水平。
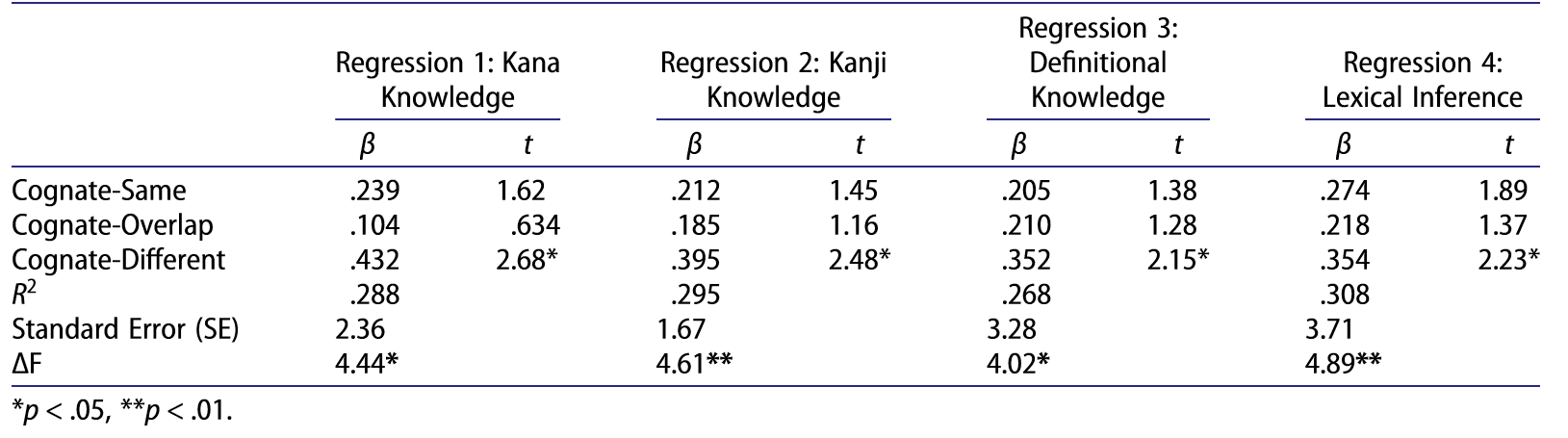
表2:37名中国老员工的语义类别判定得分对词汇的发音、正字法、含义知识、阅读理解能力预测作用的多元回归分析
此研究突破性地证实了表意文字语言中,同源词意识对第二语言词汇知识及阅读理解能力的预测效应;并且,进一步挖掘出“异义同源词”这一高预测力的变量。
在张浩敏团队的另一项研究中,对影响第二语言文本可读性的词汇特征做了语料库角度的计算与分析。文本可读性指的是阅读材料能够被读者理解的程度,即文本难度(Dale& Chall, 1948)。第二语言文本可读性研究为第二语言教材编写、阅读教学与语言测试提供了难度标准。可读性研究的基本范式可以总结为因变量难度校标与自变量文本特征的公式或模型建构,具体见图1—课题组博士生韩玉婷前期研究中对可读性研究的归纳与提炼。
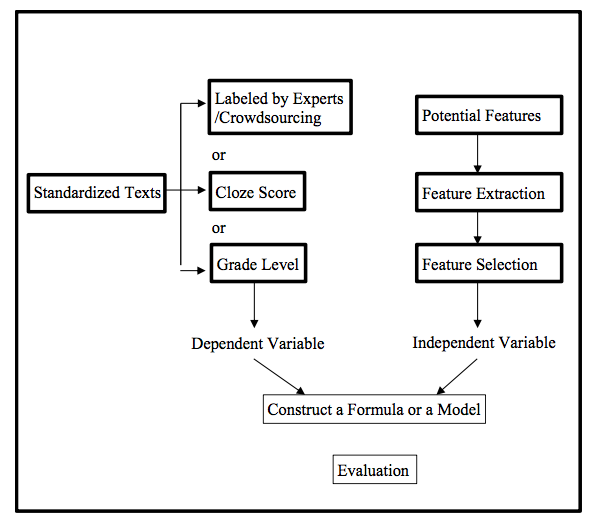
图1 可读性范式模型(引自韩玉婷、郭曙纶,2019)
在影响阅读难度的文本特征中,词汇特征的权重最高(Collins-Thompson, 2014)。那具体是词汇的什么特点影响阅读呢?张浩敏团队于2020年发表于Journal of Quantitative Linguistics的论文Frequency, dispersion and abstractness in the lexical sophistication analysis of a learner-based word bank: Dimensionality reduction and identification剖析了文本可读性中影响词汇复杂度的多个维度。张浩敏为文章的第一作者,博士研究生韩玉婷、硕士研究生崔流然、张形共同完成了此项研究。该研究基于现有的两个大型语料库--当代美国英语语料库 (COCA)和英国国家语料库(BNC),由20位语言学专业硕士生对三个中国学习者词表—初中、高中、大学英语词表进行词频、分布广度和抽象性的手动编码。研究将变量通过主成分分析进行降纬,试图找出高相关变量,并进一步提取出影响词汇复杂度的高权重变量。
研究发现:
词语的分布广度是一个独特的影响因素,而词语的词频与抽象性可以追溯到一个因子。
词汇复杂度的3个指数在3个级别的词表间有显著差异,且分布广度是区分3个级别词表的唯一显著指标。
词语的分布广度这一词汇特征在前人研究中并未被广泛提及(A. C. Graesser et al., 2011; Benjamin, 2012; Sato, 2013),分布广度在第二语言词语难度的影响得到验证为其在未来第二语言文本可读性研究中的关联计算做好了准备。
论文信息:
Zhang, H., Han, Y., Cheng, X., Sun, J., & Ohara, S. (2021). Unpacking cross-linguistic similarities and differences in third language Japanese vocabulary acquisition among Chinese college students. Journal of Multilingual and Multicultural Development. DOI: 10.1080/01434632.2020.1865987
Zhang, H., Han, Y., Zhang, X. & Cui, L. (2020). Frequency, dispersion and abstractness in the lexical sophistication analysis of a learner-based word bank: Dimensionality reduction and identification. Journal of Quantitative Linguistics.DOI: 10.1080/09296174.2020.1782716





华东师大必赢bwin线路检测中心
Copyright © bwin·必赢(中国)线路检测中心-官方网站 版权所有